[UPDATE 💡] I moved to Mountain View, California in December 2024, concluding my chapter in Tokyo!
Also, I joined Google Labs to make a new AI product for Google on July 2025, leaving Gemini App team.
Hi, I'm Jiho. I am a product developer and researcher, building products with machine learning and natural language processing (NLP).
I like to write about machine learning, NLP, AI and product development. I also write in Korean.
Currently, I am working on a new AI product that aims to innovate how people work.
I've been at Google since 2020, starting from Japan, working on these products:
Pomelli went from zero user to being introduced in Google Marketing Live in a half of year. Thousands of people worldwide are using it to grow their business.
We shipped multiple features since the first launch. Photoshoot, Product Catalog, Agent, and many more. The team’s momentum is very high. I remember one launch day, we shipped an important in the morning and planned for the next on in the afternoon.
This is all happening in less than a year since I joined Google Labs. The team is growing, too. When I first joined, I could count all engineers with one hand. Now, the team is scaling up so fast that we constantly talk about ways of work and culture. I never knew I could experience such thing in a Big Tech like Google. Perhaps, this is unique to only a few orgs like Labs, where 0-to-1 products are born, die, or grow.
Introducing Pomelli agent.
My first half of 2026 was focused in making Pomelli take off from the ground. While we have a long way to go, we have succeeded in gathering significant amount of attention internally and externally and being used by different small and medium sized businesses.
I want to share what I have learned so far from working on an experimental AI product. This is not only for sharing my knowledge, but also for my own future reference. I hope my insights are helpful for those who are working on similar projects.
System Design & Last Mile
In the era of vibe coding, people say that the cost of writing code has fallen. This may be partially true, but it does not mean that making a good product has become easier.
Vibe coding is great at creating things for the 1st time as proof-of-concepts or minimal viable prodcuts, but it only gets you to 70-80%. This is already a very impressive progress of AI tools, but it will be very challenging to get a vibe coded app working in scale reliably, once real users come in.
Once real users start using the product, basically it is equivalent as a moving train. Making changes and bug fixes reliably is same as changing the track in front of you and the train engine while the passengers are inside. Since you are not the only user, you can not simply hit “re-generate”.
For this reason, system design is still very relevant in making the product scalable and maintainable. AI agents may have the knowledge to do this, but is vulnerable to make short-sighted decisions when it writes code, unless the engineer can orchestrate the work properly. Like I said before, software engineering is larger than coding.
The “last mile” engineering, which takes the 70-80% to 90-100%, is crucial in making a good product. This may mean fixing edge case bugs, improving quality of generative AI outputs via eval & iterations, or reconsidering user workflows based on feedback.
Our team believes that the success of Pomelli came from our focus on last mile efforts before shipping. Many features were a result of team-wide feedback sessions & user research and individual members’ obsession of quality.
This also requires willingness to tolerate some less important aspects via ruthless prioritization. Perfectionism should not slow down our velocity.
Go-to-marketing (GTM) is King
Now hundreds of AI features and products are being launched every day. To cut through the noise and get our stuff into people’s attention, go-to-market (GTM) strategy is very important.
Our marketing team is very involved in the product development discussion, so that our product development and GTM strategy align seamlessly. Our team engineers can question & push the marketing plan of the launch they are working on. This shows how strong our sense of ownership is.
Google Labs GTM Team is definitely the #1 important factor in the success of our product. During our Photoshoot launch, a lot of marketing bullets - influencer partnerships, media press, and even Google leadership level (ex. Demis, Josh) amplification - were spot on.
In this noisy, fast moving world, GTM strategy is king, no matter how good your product is.
Aligning on what to build is hard
In order to move fast, alignment among the team members, especially different functions like eng, PM, and design, is very important but challenging.
I still experienced a lot of wasted time & efforts for some features, when we were not very clear on what we wanted to build. In the end, we had to rethink the values this feature wanted to bring to the user and cut out any parts that are not necessary or too difficult to achieve.
Also, effective communication and decision making are often difficult when the team is moving fast and the scope is constantly keep changing. This could cause a lot of confusion and wasted efforts, risking the team to burn out from constant back-and-forth discussions and implementations.
In a startup like team with such fast moving pace, some of these are probably inevitable. The growing team size will make this pain even larger. However, it does not mean the team cannot do better.
Our team is constantly trying to improve on this, even though it may cause uncomfortable conversations and tension. Feedback and iteration is the only way that we can keep a well-functioning team that builds a good product.
Focus on real problems, not the buzz words
Lastly, this is probably the hardest thing to do. I see a lot of people keen on using buzz words like “agent”, “harness”, etc. to convince the value of their product. This may work for some niche audience, but in reality, most people do not understand or interested in understanding these “AI” concepts.
They just want to get their problem solved. One core philosophy is to focus on solving the tangible problems of SMBs and be simple and easy so that they can use Pomelli to solve their everyday problems, leaving the underlying complicated tech behind.
–
Working on a new product is very exciting, but once it starts taking off, keeping the momentum and focusing on how the product and team should evolve are even bigger challenges.
While I’m still learning and processing this journey every day, I wanted to document these early reflections from working on Pomelli during its formative stages.
Let me know if this was interesting, and I’d love to hear your thoughts or discuss further!
Last month, I wrote about building intuition and taste and wondered how new programmers can develop these skills when AI can handle the details for them.
I didn’t have an answer. But now there’s some data.
Anthropic just published a randomized controlled trial studying how AI assistance affects skill formation. They gave junior developers a task to learn a new Python library (Trio) - half with AI assistance, half without. Then everyone took a quiz.
The results were striking: developers who used AI scored 50% on average. Those without AI? 67%. That’s nearly two letter grades of difference.
But here’s what’s interesting. The AI group wasn’t actually faster. On average, completion time was about the same. So they didn’t gain speed, and they learned less. Worst of both worlds.
–
Reading through the paper, I found myself nodding along - this matched my intuition about how skills are built through friction, not shortcuts. But then I got to the qualitative analysis, and things got more nuanced.
The researchers watched screen recordings of every participant and identified six distinct patterns of how people used AI. Three patterns led to poor learning outcomes (24-39% quiz scores). Three led to surprisingly good ones (65-86%).
The low scorers? They delegated everything to AI, progressively relied more on it, or used it as an iterative debugging crutch. This is the kind of behavior I experienced when I have low energy & motivation level, as mentioned in my previous post, Useful principles for using AI coding tools.
The high scorers did something different.
One pattern was “Generation-Then-Comprehension” - they had AI generate code, but then asked follow-up questions to understand what it did. Another was “Conceptual Inquiry” - they only asked conceptual questions and solved errors themselves. The third was “Hybrid Code-Explanation” - they asked for code and explanations together.
The highest scoring group (86% average) looked almost identical to the lowest scoring group (39%) at first glance - both used AI to generate code. The difference? The high scorers took an extra step to check their own understanding afterward.
–
This feels like empirical evidence for something I’ve been thinking about. It’s not whether you use AI, but how you use it to not only complete the task, but also to learn on the way.
The paper found that participants who encountered more errors and resolved them independently learned more. The struggle was the point. But crucially, you can still use AI and preserve that struggle - if you stay cognitively engaged.
Asking “write this function for me” is different from asking “explain how this nursery pattern works.” Both use AI. One has an opportunity to learn, but one doesn’t.
There’s a line in the paper that stuck with me. Participants in the AI group self-reported feeling “lazy” and noted “there are still a lot of gaps in my understanding.” Meanwhile, the no-AI group found the task “fun” and said the instructions helped them develop understanding.
The AI users knew they were learning less. They just couldn’t resist the shortcut.
I think this is the real challenge. It’s not about restricting AI access. It’s about developing the discipline to use it in ways that build, rather than bypass, understanding.
In my previous post, I wrote that becoming a good software engineer is less about knowledge now, and more about discipline. This research suggests the same thing from a different angle: the tools are neutral. The discipline to stay curious and wanting to learn - that’s what separates growth from stagnation.
–
Perhaps, this is not just about coding, but how AI will impact education overall. Our children will have more tech-integrated life than us. Recently, the book Anxious Generation raised awareness of the negative impacts of smartphones to our kids. AI will be a bigger wave.
This leads me to a seemingly unrelated, but deeply connected question: how do we raise a child who is curious and self-driven toward learning, even when there are just shortcuts right there? I feel like this is asking a child (or anyone really) full of marshmallows and chocolates to not eat it and just eat a bowl of salad everyday.
Being a parent myself, I have started to gain tremendous interest in the matter.
–
Recently, I read an article from the Economist, Why child prodigies rarely become elite performers. The gist was that children who specialized in a discipline too early didn’t necessarily have a higher chance of success as adults. Children who were exposed to various kinds of sports were more likely to become elite professional athletes. For example, Rafael Nadal played football until he fully committed to tennis at age 12. This was true in science and other fields as well.
There was an interesting hypothesis in this article - children who tried various sports learned how to learn.
“Learning is itself a learnable skill, and the best way to hone it is to pursue a variety of things.”
Going forward, learning how to use AI well and developing that discipline also feels like learning for the sake of learning. Perhaps the conclusion is that we need an educational shift that enables children and juniors to learn how to learn, even when shortcuts like AI exist. In a society where educational philosophies focused on outcomes are prevalent, this feels like a significant paradigm shift, but I believe this is truly the necessary direction for growing ourselves and properly educating our children.
Every time AI coding gets better, my job description gets fuzzier.
Recently, I have been trying out more new tools like Google Antigravity and Claude Code, for both work and hobby projects and it’s been an eye-opening experience.
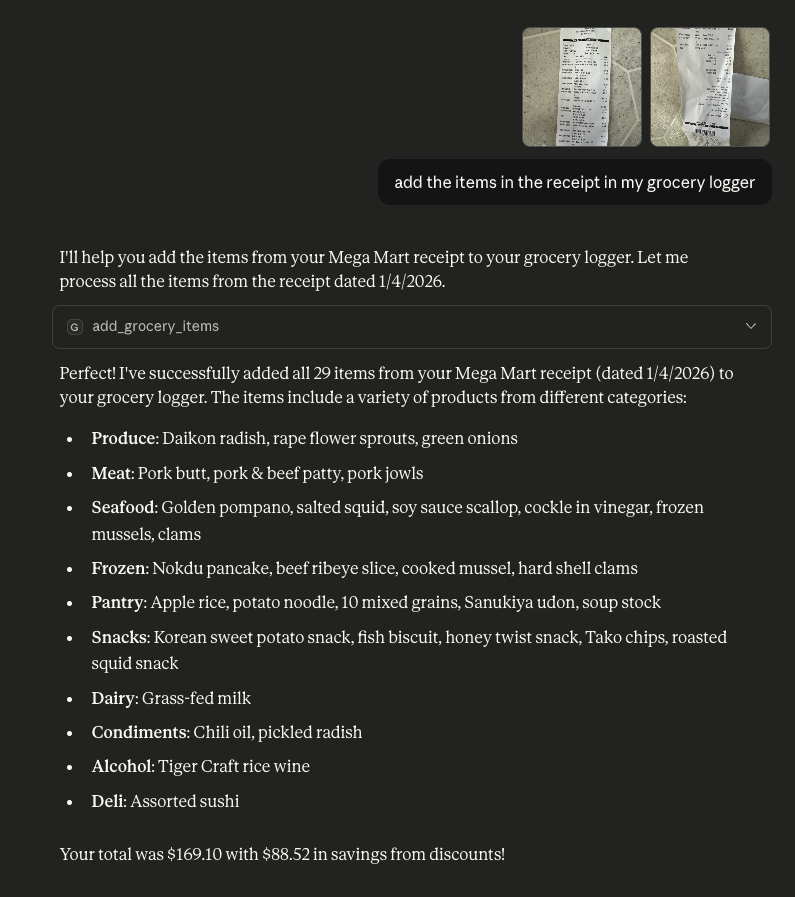
This weekend, I had a one-hour window, so I decided to try out this idea of a grocery logger, where Claude can read my grocery receipt image, categorize them, and save them into a DB. Then later, I would be able to ask questions like, “How much did I spend on meat this month?”, “Which groceries have the cheapest rice?”, or “Is this dumpling a good price?”
In my “experience”, I “knew” this involved creating a MCP (Model Context Protocol) server with a SQLite Database, so I did some quick research and found out that Claude Desktop can connect to a MCP server locally on my MacOS.
Okay, great! I started to write a prompt, which felt like drafting a design doc, listing out what functionalities I want, what the inputs and outputs are, what are the end use cases I want to support. And clicked enter.
BOOM. Claude Code wrote the MCP server, even ran commands to start the server, looked at the errors, fixed the first draft, and then completed the code. I reviewed the code and gave some suggestions. With about a 5-turn conversation, an MCP server was completed and fully integrated to Claude Desktop.
At this point, I was 15 minutes into the process. Then another 15 minutes, I was looking to deploy this server online. Claude gave me some suggestions on which free services I can use, with pros and cons. I liked one service, because I “felt” that persistency in the DB together with the server node would save me a lot of trouble. In about another 20 minutes, the server was fully deployed and I could use it on my mobile app.
I still had 15 minutes before I had to do my family chores, so I was “thinking”, maybe a fuzzy string matching of the item names might help, so I prompted.
nice, that worked. let's go back to feature development. Should we add fuzzy matching to query item_price or query_spending for robustness?
I thought it’s funny that I had to show positive sentiment here and also ask for an opinion, rather than asking Claude to implement it, but I guess I had a “gut feeling” that this feature was possibly not important, so framed it as a suggestion.
And then surprisingly Claude said:
Good question. Currently we use SQL LIKE %term% which handles partial matches but not typos. My recommendation: Skip fuzzy matching for now.
Claude is already pretty good at normalizing input before calling tools. If you say "banannas", Claude will likely call the tool with "bananas".
Wow, this kind of pushback is something a good junior engineer would do. Mind blowing!
–
I’m sure a lot of you experienced much more extensive and complicated usage of tools like this (and much earlier than me), but this got me thinking a lot. It was like hiring a super fast and smart intern, who is most likely going to get better day by day.
In order to make good use of this intern, I must be thinking at one abstraction layer higher. I need to be more like a product manager, a tech lead, and a UX designer.
PMs decide what to build. Tech leads decide how to architect it. UX designers decide how it flows. The common part? Decisions.
Intuition
Then how do you make “good” decisions? So far, the best decision makers I have seen do these two things well: (a) gather many ideas (diverge), (b) rapidly decide which ones to apply (converge).
And this requires intuition, because in most real situations, you don’t have time or complete information to analyze everything rationally with all the data in the world.
Thinking on my own, I think my intuition for software engineering is built over decades of hands-on work. I have been coding for 20+ years, since I was a teenager. For education, for fun and for work.
I can still feel the codes that I wrote for the 1st time when I was a teenager - from the command line based Blackjack and Omok game, ASP.NET website I built and maintained for our high school student community, Android client code for my first paid internship, the first Tensorflow Keras code that ran on 1 GPU in my postgraduate NLP lab, numerous data pipelines I wrote in my first team in Google, and the latest launched AI product Pomelli.
I remember one course in my 2nd year of undergrad called Computer Organization, where Assembly was taught. I had to manipulate bits with this ancient language. At that point, I didn’t really get the point of this course. It was mandatory so I took it. Looking back, the course probably didn’t have a huge impact on my skills itself, but it has somewhat contributed to developing my intuition about how the computer works under the hood. Similarly, C/C++ taught me Object Oriented Programming, and Ruby on Rails taught me the basics of web programming.
Taste is another big part of intuition that gets built by doing and trying to get the details right. It’s weird to say that software engineers have “taste”, but it is important when there is no right or wrong. I believe that some part of software engineering is a form of art, so, yes, there is definitely taste involved.
I feel like automatically generated code doesn’t build taste, at least not as effectively as writing them yourself, similar to how Spotify’s algorithm does not necessarily build new music taste.
Intuition and taste are built when you can actually sense your work and are willing to explore the unknown.
A new Generation of Software Engineer
I’m concerned about how new programmers can build intuition and taste. Why learn the details when AI can handle them for you?
But that’s exactly the trap. A good engineer will need to think for herself—deciding when to dig deeper versus when to stay high-level, and actively seeking opportunities to build intuition.
Becoming a good software engineer is less about knowledge now, and more about discipline. A healthy stubbornness to understand things even when you don’t have to. That’s harder than learning to code.
–
This isn’t just about coding, though.
Writers, designers, musicians - anyone whose craft is built through repetition (many parts of life) faces the same question: how do you develop taste when AI can do the repetition for you?
I don’t have an answer. But as a parent, I think about this constantly. I want my children to develop the intuition to write their own thoughts, design with their gut, explore music with their ears—not just consume what algorithms serve them.
Maybe I’m a traditionalist. But I’m not a pessimist. Assembly becoming Python didn’t make us worse engineers. Encyclopedias moving to Wikipedia didn’t make us stupid. We’ve adapted before.
Still—how do we build intuition in a world where AI can shortcut the hard parts? That’s a question I’ll keep thinking about.
Maybe this post is for those executives/managers who think their dev teams can all be laid off and replaced by LLM coding agents.
I heard a story from my software engineer working in finance that his stakeholder came back with some vibe coded results from ChatGPT and asked him why his team cannot fulfil his request faster. In my friend’s mind, several reasons came up - integrating to existing prod code, some weird tech debt, headcount issue, etc. - but he did not say much, because it would all just sound like an excuse to the stakeholder and make him sound incompetent. Those reasons are hard to explain to a non-technical person without enough context.
Like this anecdote, vibe coding makes our jobs look so easily replaceable. Compelling quotes from people like Jensen Huang (who has a serious stake in hyping up the idea of replacing dev team jobs with his GPUs) appear on famous business news and magazines.
What should we do? Students or juniors—should you stop pursuing this path? Seniors—should you treat this as a mid-life crisis and start looking for other occupations? I mean, how can we possibly be better than Devin, our software engineer AI?
Let me say this—not all software engineers will be replaced! (But, as always, I may be wrong, so don’t depend on my word for your career decisions).
Coding vs. Programming
There is a lot of confusion between these two words, especially among non-technical people. In order to contemplate our existential crisis, we need to clearly define these terms.
Programming is fundamentally about getting computers to work on tasks for us. These tasks are something that we do not want to do, because they are tedious, time-consuming, or too complex to do. We can also think of this as “automation”.
Coding is about giving computers instructions for these tasks. It is a way of communication. We started from punching holes in cards. Often, we need programming languages like C++ and Python, which closely resemble our common language English and mathematical expressions. Nowadays, there are also “no-code” platforms, which make it easier to instruct the computer via UI. While these are not written format, they still can be considered as “coding” as they should have some syntax to make things work (think of Scratch, the UI-based programming language, or Zapier, or recently n8n workflows).
Programming is larger than coding. A child can learn how to write the alphabet, but it is not sufficient to write a sentence. Writing a sentence is a good start, but not sufficient to write a book, let alone an essay.
Programming involves all processes that go into developing software—problem definition, planning, ideation, design, testing, and many more. Coding is just one small part.
Programming vs. Software engineering
Let’s look at even a bigger picture. Software engineering is not just about programming. Software engineers don’t build real, physical things, such as bridges or tunnels like civil engineers, but we are still called “engineers”. Why?
Because we do not just “code” to automate tasks, but we build “programs” that perform tasks not thousands, probably millions, maybe trillions of times. Such repetition needs to be reliable, lasting for a pretty long time, serving many customers. We also need to build new features. This often requires structural changes to the program, which incur constant refactoring and migrations. Doing this while maintaining stability is like changing train components while the train is running at 300 km/h!
Even before that, we need to figure out what to build. People may think that this is the role of product managers, designers, or business developers, but without the input of software engineers, such proposals can be disastrous from the beginning. Some companies do not even have other functions, so engineers need to wear those hats ourselves.
Last but not least, software engineering is mostly a team sport. Unless you are an individual, independent developer, you most likely work with a team of other software engineers and non-tech functions. This involves “social” and “management” aspects, which many of us dread, but it is necessary to get big things done. Code reviews, bug tracking, project management tools, etc. exist for this reason.
Can we be replaced by LLMs?
Now that we have defined these three terms, we can go back to the question: “Can software engineers be replaced by LLMs?”
Well, it depends.
While it is debatable whether LLMs have or will bring enough value in all industries, one thing for sure is that they have fueled the productivity of software engineers.
They can do coding pretty well with amazing speed. Apparently, a lot of our work involves “boilerplate” tasks, which were tedious and time-consuming. LLMs excel at these.
As I mentioned in my previous post, they have almost replaced Stack Overflow and a lot of API documentation reading. For example, I use the Python libraries Pandas and Matplotlib a lot, which I find the APIs not too intuitive sometimes, but using Gemini really boosted my productivity.
With some good principles as I discussed, LLM coding tools will make software engineers productive.
Being productive is one thing, but do LLMs always make the right decisions?
Context, context, context for decisions.
When Claude and Gemini came up with millions of tokens of context window, a lot of people thought: “Now, I can attend to the whole codebase, so I have all the context!”
Yes, but not enough yet. Apparently, not all contexts are documented. Some might be from a meeting that happened 2 years ago, or an office corridor chat that happened 3 minutes ago. In reality, codebases are really messy and documentation is almost never complete. Some contexts are not always accessible to LLMs.
Humans live in context—we didn’t fall from the sky. The more senior you are, the more context you need to absorb. That’s why they attend so many meetings, conferences, etc. A competent, long-tenured engineer leaving your team is going to hurt the team, because they exit with all that context.
So yes, the so-called “long” context of LLMs is not long enough to replace your engineer, who makes decisions on what and how to build things.
Conclusion
So, can LLM coding agents replace software engineers? The answer is not straightforward. LLMs have become powerful productivity tools that handle boilerplate, answer API questions, and speed up development. But software engineering encompasses far more than coding: it requires understanding undocumented context, making architectural decisions, navigating technical debt, collaborating across teams, and balancing competing priorities in real-world systems.
The stakeholder in my friend’s story saw working code from ChatGPT and wondered why the team couldn’t deliver faster. What they didn’t see was the invisible work—the context, the trade-offs, the maintenance burden, the human judgment.
Again, who knows how far LLMs will advance in 2026! Let’s just hope we can keep growing ourselves so we won’t be replaced by AI any time soon.
Launching a product is exciting, until the server goes down after 3 hours. Users were complaining on Twitter and Discord that they cannot get in.
I joined Google Labs this July and was fortunate enough to get a chance to experience a product launch only after 3 months! Let me share what happened and some thoughts.
What is Pomelli
Pomelli is an AI marketing tool for small and medium sized businesses. It understands each business and brand and helps one to easily create marketing campaigns and creatives, tailed to each business. Read more in the Google Keyword Blog.
Generate the business DNA
Create your marketing campaigns
Generate in-brand creatives.
This was a beta launch, now only available in USA, Canada, Australia, and New Zealand. Hopefully, we can launch in more countries next year!
Launch Day
The morning we launch, the team was thrilled. We had a live dashboard to see real traffic coming in. It was supposed to be a relatively a silent launch, but we got a lot of attention in X (Twitter) and other channels.
But then the things were not working after 3 hours. Our servers were not responding properly. Users started complaining that they cannot go to the next stage of the product.
Apparently, things were melting on the component that I worked on. We had to analyze what’s going on and figured some part of the code was problematic. I had to do an emergency bug fix to cut that part of the code out, without too much sacrifice of the original feature.
I deployed the code, hoping that things would work again. However, it didn’t. By this time, users were blocked for several hours. We were even considering to put the curtains down, saying that we will be back later.
But then my amazing colleague detected another, potentially relevant, issue in the server. He started working on a fix. Things came back to normal. We announced to the users that we experienced a distruption due to unexpected amount of traffic, but we fixed the issue.
It was almost midnight when things concluded. We could all go to bed that day.
Takeaways
Good problem to have
Our PM director, Jaclyn, wrote in her blog, reflecting the launch.
She called this the Sucess Disaster. Because we were successful to get attention and traffic, problems revealed.
“This is the kind of problem you want to have. The reason things went wrong was because something went incredibly right.”
This view blew me away, not only because it is such a positive perspective, but also because it is such an accurate take. We would have never caught this issue with only hundreds of users, but only by having thousands or even more users using the product.
In the end, we are having unbelieveable amounts of users coming in and trying out our product!
Early Experiment
The philosophy of Google Labs is to launch early and validate fast. In a huge company like Google, it may be hard to have this kind of mentality and environment. Google Labs is literally a product labatory to avoid falling into such trap.
Just go take a look at labs.google and see what we are doing. There are many things that are hard to imagine a large company like Google would work on.
After launching Pomelli, I am now starting to understand and experience what this philosophy actually means.
The bigger picture
That does not mean that we are aiming for small things. We are launching fast, but these are just seeds of something that is potentially much bigger.
For example, Pomelli is not just another content generation tool, but it may become an ultimate AI operating platform for small and medium sized businesses, which Google has traditionally not been great at. Forbes already analyzed the potential of our product!
For this reason, we need to think big and look multiple steps ahead, but need to start somewhere.
–
This launch is one of the highlights of my whole programming career. I’m very happy that I decided to join this org and team and launch something with the team so fast.
We will continue to launch more features into Pomelli.
I am learning and experiencing a lot of interesting product and engineering problems, so I’m looking to write more on those things.

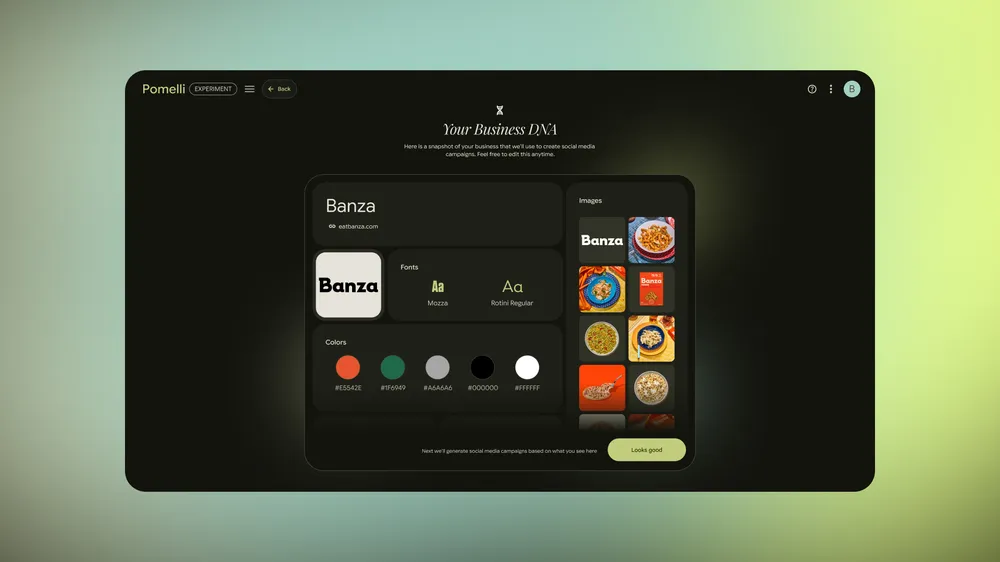 Generate the business DNA
Generate the business DNA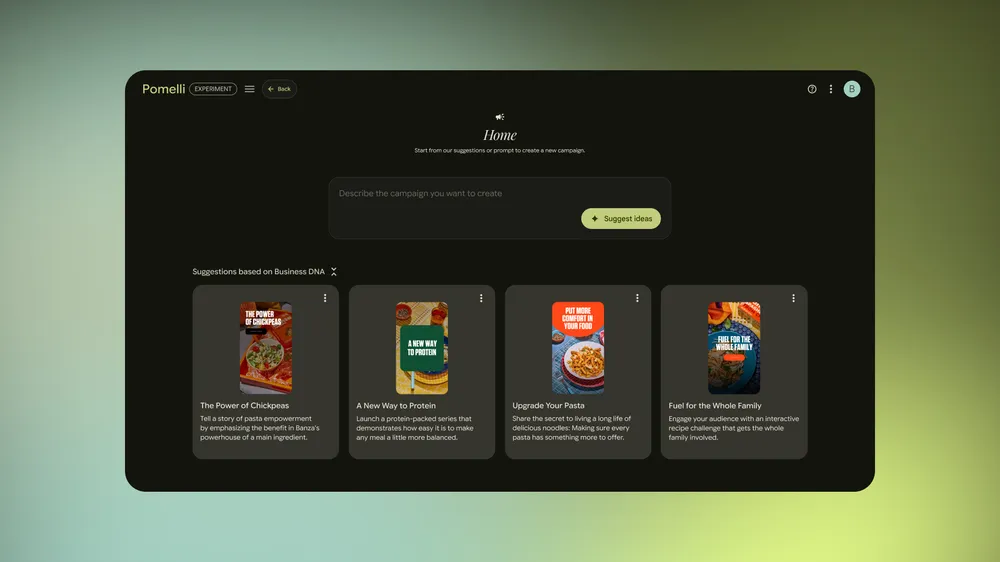 Create your marketing campaigns
Create your marketing campaigns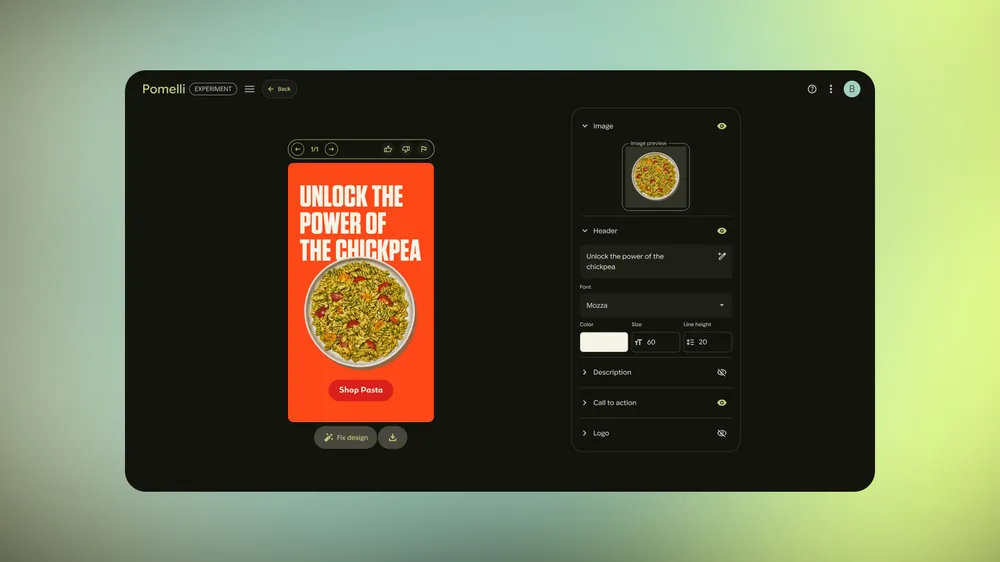 Generate in-brand creatives.
Generate in-brand creatives.